📊 概率与统计:数据分析与随机模型
掌握从计数原理到概率分布,再到统计推断的完整逻辑链条。
🔹 计数原理与排列组合
第 22 章 计数原理
22.00 知识网络
Link to original

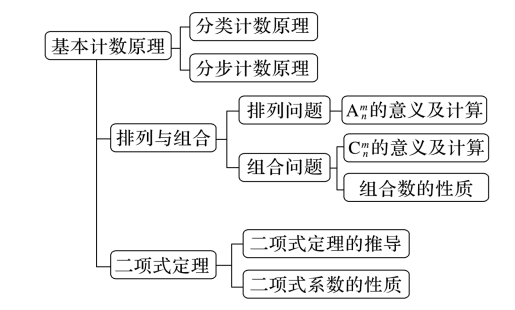
22.01 计数原理、排列与组合
🟦 计数原理、排列与组合专题
核心心法
“分类用加法,分步用乘法;有序选排列,无序选组合”。计数原理是解决“有多少种可能”的底层逻辑。排列关注的是元素的位置顺序,而组合关注的是元素的选取结果。掌握排列组合数之间的倍数关系(),能帮助你理清复杂计数问题中的逻辑层次。
一、 计数原理 (Counting Principles)
1. 分类加法计数原理
- 定义:完成一件事有 类办法,各步方法相互独立。
- 公式:。
- 特点:每种方法都能直接独立完成这件事。
2. 分步乘法计数原理
- 定义:完成一件事需要分成 个必经步骤,各步相互依存。
- 公式:。
- 特点:必须完成所有步骤,这件事才算完成。
二、 排列 (Permutation)
1. 定义与排列数
- 排列:从 个不同元素中取出 个, 排成一列。
- 排列数:所有不同排列的个数,用 表示。
2. 排列数公式
- 一般公式: ()。
- 全排列:。规定 。
3. 排列数的性质
- ①
- ② (常用于数列裂项求和)
三、 组合 (Combination)
1. 定义与组合数
- 组合:从 个不同元素中取出 个(不考虑顺序)。
- 组合数:所有不同组合的个数,用 表示。
2. 组合数公式
- 计算式: ()。
- 规定:。
3. 组合数的性质
- ① 对称性:。
- 若 ,则 或 。
- ② 递推性 (杨辉三角基础):。
四、 排列数与组合数的关系
- 理解:从 个中取 个的排列过程,可以看作先“组合”(取出 个),再“排列”(将这 个全排列)。
⚠️ 考场避坑与做题技巧
“有序”还是“无序”的判定
拿到题目先自问:“换个位置,结果变吗?”。如果换位置结果变了(如排队、发职务、组数字),用排列 ;如果换位置结果不变(如选代表、抽样检查、配菜),用组合 。
防止重复与遗漏
分类计数时,要确保各类别之间不重不漏;分步计数时,要确保各步骤之间连续且完整。
Link to original处理排列组合的常用模型
- 相邻问题:捆绑法(将相邻元素视为一个大元素)。
- 不相邻问题:插空法(先排其他元素,再将不相邻元素插入空位)。
- 定序问题:除法倍数法(总排列数除以定序全排列)。
- 至多/至少问题:反难则易(使用间接法,总数减去不符合要求的情况)。
22.02 排列组合 16 种核心解题模型与策略
🟦 排列组合 16 种核心解题模型与策略
核心心法
“结构定模型,限制定顺序”。排列组合问题的复杂性源于各种限制条件(相邻、不相邻、定序、重复等)。掌握这 16 种核心模型,本质上是掌握了将复杂计数问题“降维”为基础加乘原理的工具箱。
1. 特殊元素和特殊位置优先安排
- 核心思想:优先处理有特殊限制的元素(如“首位不为0”)或位置(如“末位为奇数”),消除矛盾。
- 例:0,1,2,3,4,5 组成无重复五位奇数。
- 步1:末位 ;步2:首位 (不为0且不为末位);步3:余位 。
- 结论:。
2. 相邻元素捆绑法
- 核心思想:相邻元素看作一个整体(大元素),排完后再考虑内部排列。
- 例:7人站一排,甲乙相邻且丙丁相邻。
- 步1:整体排 ;步2:内部自排 。
- 结论:。
3. 不相邻问题插空法
- 核心思想:先排无限制元素,再将不相邻元素插入形成的空隙中。
- 例:4个舞蹈、2个相声、3个独唱,舞蹈不连续。
- 步1:排余项 ;步2:插空位 (5个元素形成6个空)。
- 结论:。
4. 定序问题整除法
- 核心思想:先全排列,再除以定序元素的全排列数以消除顺序影响。
- 例:7人排队,甲乙丙3人顺序一定。
- 结论:。
5. 重排问题求幂法
- 核心思想:允许重复抽取,每一步的选择数均相等。
- 例:6名实习生分配到7个车间。
- 结论:。
6. 圆排列问题
- 核心思想:圆排列无首尾,需固定一个元素。
- 结论: 个不同元素圆排列种数为 。
7. 多排问题直排法
- 核心思想:将多排位置拉直成一排来处理。
- 例:8人前后两排各4人,甲乙前排,丙后排。
- 结论:。
8. 排列组合混合问题先选后排
- 核心思想:先从总体中选出符合要求的元素组,再对这组元素进行排列。
- 例:5个球装入4个盒,每盒至少一个。
- 步1:选2球绑在一起 ;步2:4个元素排入4盒 。
- 结论:。
9. 小集团问题先整体后局部
- 核心思想:类似于捆绑法,但侧重于集团内外的多层次排列。
- 例:1-5组成五位数,恰有两个偶数夹在1,5之间。
- 结论:(整体排 1,5自排 偶数自排)。
10. 元素相同问题隔板法 (Star and Bars)
- 核心思想:在相同元素的空隙中插入“挡板”进行分配。
- 例:10个名额分给7个班,每班至少一个。
- 结论:。
- 模型扩展:
- 正整数解:。
- 非负整数解:。
11. 正难则反总体淘汰法
- 核心思想:当正面分类过多时,用总数减去违规数。
- 结论:。
12. 不同元素分组分配法
- 核心思想:先分组(注意均匀分组需除以 ),再分配。
- 均匀分组判定:若有 组元素个数相等,需除以 。
13. 合理分类与分步
- 核心思想:寻找“全能型”关键元素作为分类标准。
14. 错位排列 (Derangement)
- 核心思想:每个元素都不在对应位置。
- 常用数:。
15. 分解与合成策略
- 例:30030 的偶因数个数。
- 核心:必须含质因数 2,其余 5 个质因数任取。
- 结论:(即 )。
16. 特殊模型
- 异面直线对:。
- 圆内交点:。
- 连续号码:。
- 传球递推:。
⚠️ 考场避坑与做题技巧
隔板法的使用前提
隔板法只能用于相同元素(如名额、一样的球)分给不同对象(如班级、盒子)。如果球是不同的,必须使用分组分配法。
重复计数的重灾区
在“平均分组”问题中,如 4 人平均分成两组,如果不除以 ,就会将 与 的组合计算两次。
Link to original“至少”不一定都要用间接法
当“至少”的情况只有 1-2 类时,直接分类计算往往比总数减去反面更不容易出错。
22.03 二项式定理全总结
🟦 二项式定理全总结 (Binomial Theorem)
核心心法
“通项定位置,赋值定系数”。二项式定理的核心在于对 展开结构的把握。通项公式 是解决特定项问题的钥匙;而面对复杂的系数和问题,“赋值法”则是化繁为简的神技。
一、 二项式定理及通项公式
1. 基本公式
- 项数:共有 项。
- 二项式系数:。
2. 通项公式 (General Term)
- 用途:求指定项(如第 3 项)、有理项(指数为整数)、常数项等。
3. 特殊形式
- (1+x)ⁿ:
- (a-b)ⁿ: (注意符号交替)
二、 二项式系数的性质
- 对称性:(与首末两端等距离的系数相等)。
- 增减性与最大值:系数从两端向中间先增后减。
- 为奇数:中间两项 和 相等且最大。
- 为偶数:中间一项 最大。
- 系数和公式:
- 全系数和:
- 奇/偶项系数和:
三、 赋值法求系数和 (The Assignment Method)
设 :
- 常数项:
- 所有项系数和:
- 正负交替和:
- 绝对值系数和:
- 进阶技巧 (导数法): 对 求导并令 ,可求 。
四、 系数最大(小)项的求法
设第 项的系数为 :
- 求最大系数项:解不等式组
- 求最小系数项:解不等式组
五、 二项式定理的其他应用
- 整除问题:将数字拆分为 ,通常取 为除数的倍数(如 判定被 7 除的余数)。
- 不等式证明:结合放缩法。
- 近似计算:当 时,。
- 整数与小数部分 (共轭构造): 利用 与 配对(对偶式),因对偶式通常在 之间,从而锁定整数部分。
⚠️ 考场避坑与做题技巧
区分“二项式系数”与“项的系数”
- 二项式系数:仅指 ,与 中的具体数值无关,永远为正。
- 项的系数:通项 中除了变量之外的所有常数部分,包含正负号。
通项公式的下标陷阱
通项是 ,这意味着第 5 项对应的是 。在计算时千万不要把 直接当成项数。
Link to original有理项的判定
求有理项时,将 化简为变量 的 次方形式,解方程使 ,且 。
🔹 概率初步与古典概型 (第 14,15 章)
第 14 章 统计
14.00 知识网络
Link to original

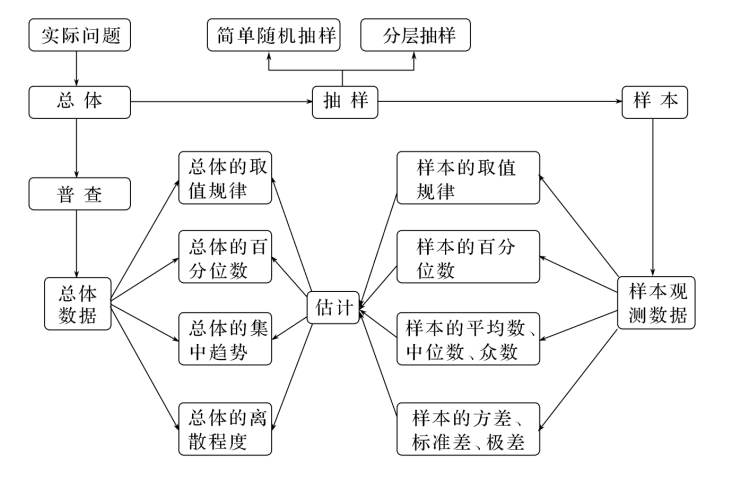
14.01随机抽样、平均数与方差
🟦 统计学基础:随机抽样、平均数与方差 (Statistics)
核心心法
“样本推断总体,分层化繁为简”。统计学的核心是通过科学的抽样方法(如简单随机抽样、分层随机抽样)获取具有代表性的样本,并利用平均数(集中趋势)和方差(离散程度)来定量描述总体的特征。
一、 随机抽样 (Random Sampling)
1. 调查方式
- (1) 全面调查:对调查对象全体逐一调查(如人口普查)。
- (2) 抽样调查:从总体中抽取部分个体调查,以此推断总体情况。核心是样本需具有代表性。
2. 基本概念
- 总体:调查对象的全体。
- 个体:组成总体的每一个调查对象。
- 样本:从总体中抽取的部分个体。
- 样本容量:样本中包含的个体数量。
3. 抽样方法
- 简单随机抽样:
- 放回式:每次抽取后放回,个体概率始终相等。
- 不放回式(常用):每次抽取后不放回,个体概率始终相等。
- 分层随机抽样:
- 按变量将总体划分为互不重叠的层,各层独立抽样。
- 比例分配:每层的样本量与该层的大小成比例。
二、 平均数的计算 (Mean)
- 普通平均数:
- 加权平均数: ( 为频率)
- 分层抽样的总平均数 ():
- 两层:
- 三层:
三、 方差与标准差 (Variance & Standard Deviation)
1. 基本计算
- 普通方差:
- 加权方差:
- 标准差:。刻画数据的离散程度, 越大波动越大。
2. 分层抽样的方差公式
若两层样本分别为 和 ,总平均数为 :
🔍 证明简述: 利用方差定义式展开,通过添加项 进行平移,利用 的性质简化交叉项,最终合并为各层方差与各层均值偏离度的加权和。
- 三层情况:
四、 数据的线性变换结论 (Linear Transformation)
若新数据 ,原数据特征为 ,则新特征如下:
统计量 变换公式 备注 平均数 随 同步平移伸缩 方差 与常数 无关 百分位数 保持顺序关系 众数 对应位置平移 极差 $R_y = a
⚠️ 考场避坑与做题技巧
分层方差的物理意义
分层方差公式由两部分组成:层内方差()和层间方差()。如果各层均值差异很大,即使各层内部很稳定,总方差也会非常大。
方差计算的捷径
在手动计算方差时,优先使用公式 (平方的平均减去平均的平方),这通常比直接用差值平方和计算量更小。
Link to original抽样概率的公平性
无论是不放回抽样还是分层抽样,在没有任何附加信息的情况下,总体中每个个体被抽到的概率都是 。这是判断抽样方法是否科学的核心标准。
14.02 百分位数与四分位数
🟦 百分位数与四分位数 (Percentiles & Quartiles)
核心心法
“位置决定数值”。百分位数是刻画数据分布特征的重要指标,它不仅反映了数据的集中趋势,更体现了数据在整体中的相对排位。通过将数据“切片”,我们可以直观地观察到不同比例段的数据水平。
一、 第 百分位数的概念
一般地,一组数据的第 百分位数是这样一个值,它满足:
- 这组数据中至少有 的数据小于或等于这个值;
- 且至少有 的数据大于或等于这个值。
二、 计算步骤 (三步走法则)
对于一组包含 个数据的样本,计算第 百分位数的步骤如下:
- 第一步:排序 将原始数据按从小到大的顺序排列。
- 第二步:计算指数 利用公式计算位置指数:。
- 第三步:判定取值
- 情况 A:若 不是整数,记大于 的比邻整数为 ,则第 百分位数为第 项数据。
- 情况 B:若 是整数,则第 百分位数为第 项与第 项数据的平均数。
三、 四分位数的概念 (Quartiles)
四分位数是将一组数据等分为四部分的三个数值点:
名称 百分位对应 常用简称 第一四分位数 第 25 百分位数 下四分位数 () 第二四分位数 第 50 百分位数 中位数 () 第三四分位数 第 75 百分位数 上四分位数 ()
⚠️ 考场避坑与做题技巧
整数判定是核心
很多同学在 是整数时直接取第 项,这是错误的。请记住:整数取均值,小数向上取。例如 取第 4 项, 则取第 3、4 项的平均数。
中位数的两种求法
注意百分位数求法与传统初中中位数求法(奇数取中间,偶数取平均)在逻辑上是完全统一的。当 时,套用上述三步走法则所得结果与传统中位数定义一致。
Link to original百分位数的应用背景
在大型考试(如高考、SAT)中,百分位数常用来表示考生的相对排位。如果你处在第 90 百分位数,意味着你超过了 90% 的考生。
14.03 频率分布直方图中的数据计算
🟦 频率分布直方图中的数据计算 (Data Calculation in Histograms)
核心心法
“以面积代频率,以中值代区间”。在频率分布直方图中,小长方形的面积即为频率,其总和恒等于 1。处理直方图数据的关键在于“估算”:用组中值代表组内个体的平均水平,用线性插值法锁定百分位数的精确位置。
一、 频率分布直方图的含义
- 核心定义:频率分布直方图以面积的形式反映了数据落在各个小组的频率大小。
- 基本性质:
- 各个小长方形的面积 。
- 各个小长方形的面积总和等于 1,即样本数据落在整个区间的频率为 1。
二、 样本平均数的估算
在频率分布直方图中,认为每一组的数据都集中在该组的组中值上: 设 为第 组的组中值, 为第 组的频率,则样本平均数 为:
三、 百分位数的计算 (面积分割法)
在频率分布直方图中,通常认为数据均匀分布在各自的区间上。
1. 确定所在组
计算第 百分位数时,先寻找第一个累积面积大于或等于 的小组 :
2. 精确值求解 (线性插值)
设第 组对应的区间为 ,第 百分位数为 ,则满足:
- 几何意义:直线 左侧所有小长方形的面积之和恰好为 。
四、 样本方差的估算
利用组中值和频率进行加权计算: 设 为组中值, 为频率, 为前述估算的平均数,则方差 为:
⚠️ 考场避坑与做题技巧
纵轴的含义
频率分布直方图的纵轴是 ,而不是频率本身。计算频率时务必用纵轴高度乘以组距,这是初学者最容易忽略的细节。
百分位数的快速定位
寻找中位数(第 50 百分位数)时,如果前两组面积和为 0.3,第三组面积为 0.4,那么中位数一定在第三组内,且位于该组的前一半(因为 )。
Link to original估算值的局限性
直方图计算出的平均数、方差和百分位数均为估算值。因为在计算过程中,我们假设了组内数据是均匀分布或全部集中在中点,这与原始数据的真实值可能存在微小偏差。
第 15 章 概率
15.00 知识网络
Link to original

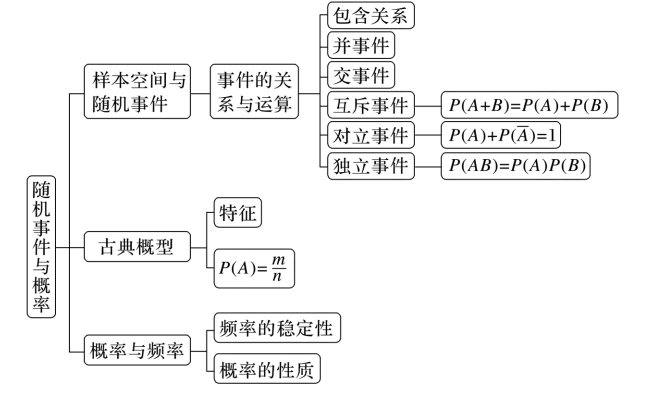
15.01 古典概型
🟦 古典概型 (Classical Probability Model)
核心心法
“有限等概,计数求比”。古典概型是概率论中最理想、最基础的模型。它的核心在于两个前提:一是可能的结果必须是有限的,二是每个结果发生的几率必须是完全公平的。解题的关键在于准确计数样本点的个数。
1. 古典概型的特点
一个随机试验若满足以下两个条件,则称为古典概型:
- (1) 有限性:样本空间 中的样本点只有有限个。
- (2) 等可能性:每个样本点发生的可能性完全相等。
2. 古典概型事件 的概率计算
在古典概型下,事件 发生的概率 等于事件 所包含的样本点个数与样本空间 中样本点总数的比值:
⚠️ 考场避坑与做题技巧
计数方法的选择
在古典概型中,计算样本点个数常用到以下方法:
- 列举法:适用于样本点较少的情况。
- 列表法:适用于涉及两个元素(如掷两枚骰子)的试验。
- 树状图法:适用于涉及多个步骤或分阶段抽取的试验。
“等可能性”的检查
并不是所有有限样本空间的试验都是古典概型。例如,“投篮命中或不命中”虽然只有两个结果,但命中率通常不等于不命中率,因此不能直接套用古典概型公式。
Link to original有序与无序的区别
在计数时,必须保持分子(事件 )与分母(样本空间 )在“是否有序”上的一致性。如果分母考虑了抽取的顺序,分子也必须考虑顺序,否则概率计算会出错。
15.02 随机事件、关系与独立性
🟦 概率论基础:随机事件、关系与独立性 (Probability Theory)
核心心法
“样本驱动事件,逻辑决定计算”。概率论的研究始于对随机现象的观察。通过样本空间刻画所有可能结果,利用集合论语言(交、并、补)定义事件关系,并以“独立性”作为概率乘法公式的逻辑基石,从而实现从频率估算到理论概率的跃迁。
一、 基本概念 (Basic Concepts)
1. 随机试验 (Random Experiment)
具备以下特点的试验称为随机试验:
- ① 相同条件下可重复。
- ② 可能结果不止一个,且事先明确所有可能结果。
- ③ 试验前不能确定哪一个结果会出现。
2. 样本空间与样本点
- 样本空间 ():所有可能结果组成的集合。
- 样本点 ():样本空间的元素,即每个可能的基本结果。
3. 随机事件
- 事件:样本空间 的子集,常用 表示。
- 基本事件:由单个样本点组成的单点集。
- 必然事件 ():在每次试验中总是发生,。
- 不可能事件 ():在每次试验中都不发生,。
注意
概率为 1 的事件不一定是必然事件;概率为 0 的事件不一定是不可能事件。
二、 事件的关系、性质及概率计算
1. 包含与相等
- 包含 ():若 发生则 必发生。性质:。
- 相等 (): 且 。性质:。
2. 并、交、互斥与对立
- 并事件 (和事件 ): 与 至少有一个发生。
- 通用公式:
- 交事件 (积事件 ): 与 同时发生。
- 互斥事件: 和 不能同时发生()。
- 性质:。
- 对立事件 ():有且仅有一个发生。
- 性质:。
三、 事件的相互独立性 (Independence)
1. 定义
对于任意两个事件 和 ,若满足: 则称事件 与 相互独立。
2. 性质
- (1) 特殊事件:必然事件 和不可能事件 与任意事件相互独立。
- (2) 四组独立:若 与 独立,则 与 、 与 、 与 也相互独立。
🔍 证明(以 与 为例)
,且 与 互斥: 证毕。
3. 三个事件的独立性
若三个事件 两两相互独立,需满足三个交事件的积公式。
注意:两两独立不能推出 ,反之亦然。
四、 频率与概率
- 频率的稳定性:随着试验次数 的增大,频率 会逐渐稳定于概率 。
- 应用:实际应用中,可以用频率估计概率。
⚠️ 考场避坑与做题技巧
互斥与独立的区分 (高频错点)
- 互斥是指两个事件“能不能同时发生”(集合关系)。
- 独立是指一个事件发生与否“影不影响另一个发生的概率”(概率关系)。
- 若 ,互斥事件一定不独立,独立事件一定不互斥。
对立与互斥的区别
对立是互斥的加强版。互斥要求“不能同时发生”(可以都不发生),而对立要求“有且仅有一个发生”(必须发生一个)。
Link to original利用独立性简化计算
当题目出现“同时发生”、“相继发生”或“互不影响”等关键词时,优先考虑乘法公式 。对于复杂的并事件 ,有时计算对立事件 会更简单。
🔹 随机变量及其分布 (第 22 章)
第 22 章 概率
23.00 知识网络
Link to original

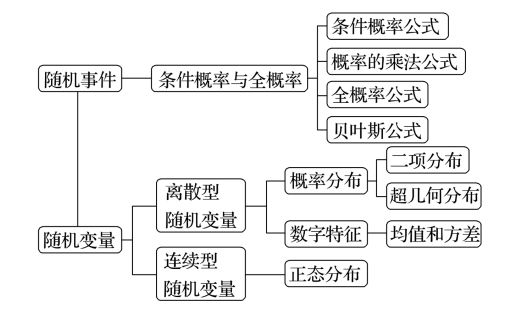
23.01 条件概率与乘法公式
🟦 条件概率与乘法公式专题
核心心法
“空间收缩,信息更新”。条件概率的本质是:当我们得知事件 已经发生时,样本空间从全集 缩小到了集合 。此时研究 的概率,实际上是在研究“ 发生的部分里有多少属于 ”。
一、 条件概率 (Conditional Probability)
1. 定义
设 为两个随机事件,且 ,则在事件 发生的条件下,事件 发生的条件概率定义为:
- :积事件 包含的样本点个数。
- :事件 和 同时发生的概率。
二、 概率的乘法公式 (Multiplication Rules)
1. 两个事件的乘法公式
若 ,则:
- 独立性简化:若 与 相互独立,则 ,公式变为 。
2. 三个事件的乘法公式
当 时:
3. 个事件的递推乘法公式
当 时:
三、 条件概率的性质
条件概率在已知 发生的“新世界”里,依然服从概率公理化定义的所有基本性质:
- 规范性:。
- 可列可加性:若 与 互斥,则 。
- 对立性:。
⚠️ 考场避坑与做题技巧
“”与“”的区别
- :在全样本空间里,看 同时发生的可能性(分母是 )。
- :已经站在 的地盘上了,看 发生的可能性(分母是 )。 口诀:前者是“两件事都发生的概率”,后者是“已知一件事后另一件发生的概率”。
注意概率树的权重
在使用乘法公式解决连抽问题(如:不放回抽样)时,概率树的每一条路径都是通过乘法公式计算出来的。路径末端的概率等于沿途所有分支概率的乘积。
Link to original独立性的判定
很多同学容易混淆“互斥”与“独立”。
- 互斥:不能同时发生,。
- 独立:互不影响,。 如果 独立且 ,那么它们一定不互斥。
23.02全概率、贝叶斯公式与马尔可夫游走模型
🟦 全概率、贝叶斯公式与马尔可夫游走模型
核心心法
“全概求果,贝叶斯溯因,游走定递推”。全概率公式是处理“多原因导致单一结果”的利器;贝叶斯公式则是在已知结果发生时,反推各原因可能性的概率罗盘;而在处理更高级的随机过程(如游走模型)时,全概率公式则化身为建立递推数列的数学工具。
一、 全概率公式与贝叶斯公式
1. 全概率公式 (Law of Total Probability)
- 前提: 构成样本空间的一个划分(两两互斥且并集为 )。
- 公式:对任意事件 ,有
- 几何直观:将事件 的概率看作是在各个“原因” 下发生的概率加权平均。
2. 贝叶斯公式 (Bayes’ Theorem)
- 定义:已知事件 已经发生,推测是由某个特定原因 引起的概率。
- 公式:
- 意义:后延概率(执果索因)。
二、 递推方法与一维马尔可夫过程
1. 简单随机游走模型 (Random Walk)
- 模型设定:点在整数点移动,向左概率为 ,向右概率为 ()。
- 递推式推导:记 为从位置 出发最终到达目标(如 点)的概率。 由全概率公式,考虑第一步的去向:
- 边界条件 (吸收壁):若 和 是终点,则 。
2. 含原地不动的随机游走模型
- 模型设定:向左(概率 )、原地不动(概率 )、向右(概率 ),且 。
- 递推方程:
- 处理技巧:通常将 项移至左侧,转化为 ,进而利用特征方程解递推数列。
⚠️ 考场避坑与做题技巧
全概率公式的“树状图”法
面对多阶段概率问题,画出概率树。第一层的分支即为 ,第二层的分支即为条件概率 。所有到达目标 的路径末端乘积之和,即为 。
贝叶斯公式的“先验”与“后验”
- 先验概率 :在实验前已知的原因概率。
- 后验概率 :在得知结果 后,修正后的原因概率。 审题时若看到“已知…发生,求是…的概率”,必用贝叶斯。
Link to original递推式的“算术性”
在随机游走中,若 ,则递推式 表明 是一个等差数列。结合边界条件可以极速求出各点概率。
23.03 离散型随机变量及其数字特征
🟦 离散型随机变量及其数字特征
核心心法
“分布定全局,期望定中心,方差定波动”。离散型随机变量的分布列是其灵魂,它完整描述了所有可能结果及其发生的概率;而数学期望和方差则是描述这一随机现象的两大核心指标。掌握线性变换下的数字特征变化规律( 与 ),是快速处理复杂统计问题的关键。
一、 离散型随机变量及其分布列
1. 随机变量 (Random Variable)
- 概念:对样本空间 中每个样本点 ,都有唯一实数 对应。
- 分类:
- 离散型:取值可以一一列举(如:投掷骰子的点数)。
- 连续型:取值无法列举,充满一个区间(如:摄入卡路里数值)。
2. 分布列 (Probability Distribution)
对于离散型随机变量 ,其取值 对应的概率 :
- 性质:
- 非负性:。
- 规范性:。
二、 离散型随机变量的数字特征
1. 数学期望 (Mathematical Expectation)
- 定义:反映 取值的平均水平。
- 线性变换:若 ,则:
2. 方差与标准差 (Variance & Standard Deviation)
- 方差定义:反映 偏离均值的波动程度。
- 标准差:。
- 线性变换:
🚀 深度拓展:方差的简化计算公式
在实际计算中,直接使用定义式往往计算量巨大,通常使用简化公式:
🔍 公式证明:
D(X) &= \sum_{i=1}^{n}(x_i-E(X))^2p_i \\ &= \sum_{i=1}^{n}[x_i^2 - 2x_iE(X) + E^2(X)]p_i \\ &= \sum_{i=1}^{n}x_i^2p_i - 2E(X)\sum_{i=1}^{n}x_ip_i + E^2(X)\sum_{i=1}^{n}p_i \\ &= E(X^2) - 2E(X) \cdot E(X) + E^2(X) \cdot 1 \\ &= E(X^2) - E^2(X) \end{align*}$$ --- ## ⚠️ 考场避坑与做题技巧 > [!TIP] **期望与算术平均值的区别** > > 算术平均值是实验后的样本统计量,而数学期望是实验前的理论预测值。但在实验次数 $n \to \infty$ 时,样本平均值会趋近于期望值。 > [!CAUTION] **方差计算中的“平移不变性”** > > 注意到 $D(aX+b) = a^2D(X)$。这意味着给随机变量加上一个常数 $b$,其方差**保持不变**。因为平移不会改变数据的波动结构,只有伸缩变换(乘 $a$)会改变波动。 > [!IMPORTANT] **$E(X^2)$ 的含义** > > 在简化公式中,$E(X^2)$ 是指取值的平方与其对应概率的乘积之和,即 $\sum x_i^2 p_i$。千万不要把它误认为是 $(E(X))^2$。Link to original
23.04 二项分布与超几何分布
🟦 二项分布与超几何分布核心考点专题
核心心法
“放回独立二项式,不放组合超几何”。判定模型的关键在于:每一轮抽样是否会改变下一轮的概率。若概率恒定且相互独立,则是二项分布;若样本总量有限且不放回,则是超几何分布。在计算期望时,二项分布的 与超几何分布的 在形式上具有高度的统一性(均是次数乘以单次成功的概率)。
一、 两点分布 (Bernoulli Distribution)
作为所有复杂分布的基石,两点分布描述的是只有两个结果(成功/失败)的单次试验:
0 1
二、 二项分布 (Binomial Distribution)
1. 重伯努利试验
- 定义:同一个伯努利试验独立地重复进行 次。
- 特征:每次试验结果相互独立,且成功概率 保持不变(通常对应“有放回”抽取)。
2. 概念与分布列
若 表示事件 发生的次数,则 :
3. 期望与方差
- 期望:
- 方差:
期望公式的推导核心
利用组合数恒等式 ,将求和式转化为二项式展开的逆过程,最终得到 。
三、 超几何分布 (Hypergeometric Distribution)
1. 概念 (不放回抽取)
产品总量 ,次品量 ,不放回抽取 件。 为抽得的次品数: 其中 的范围受限于 。
2. 期望与方差
- 期望:
- 方差: (注:解答题中不可直接使用)
四、 深度拓展:类超几何分布 (顺序抽样)
当题目要求“一次一次抽取直到某条件停止”时,考虑顺序:
例题:9球(3红6白),不放回每次取1个,直到取出3个红球停止,求第4次停止的概率。 解析:
- 意味着前3次中恰有2个红球,且第4次必取到红球。
- 计算式:(或利用组合思想分步计算)。
- 通用策略:将相同球视为不同球,分子分母统一带顺序。
⚠️ 考场避坑与做题技巧
二项分布与超几何分布的“近似”转化
当产品总量 非常大且抽取的样本 相对很小时(如 ),不放回抽样可以近似看作有放回抽样。此时超几何分布可以用二项分布来近似计算。
计算量的控制
超几何分布的计算涉及大量组合数,容易算错。建议先化简分母 ,利用对称性 来减小运算压力。
Link to original期望的“直觉”检验
无论是 还是 ,本质上都是“抽样次数 成功的胜率”。如果算出来的期望值超出了抽样总数 或成功总数 ,那一定是公式记反了。
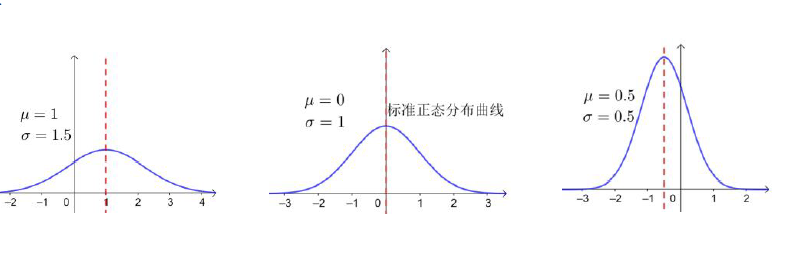
23.05 正态分布
🟦 正态分布性质与 原则专题
核心心法
“均值定位置,方差定形状,对称求概率”。正态分布 的灵魂在于其对称轴 。无论曲线如何“矮胖”或“瘦高”,其总面积恒为 1。掌握标准正态化公式 ,是将一般正态分布转化为可查表的标准正态分布 的万能钥匙。
正态分布的概念 若连续型随机变量 的概率密度函数为: 其中 为常数,且 ,则称 服从正态分布,简记为 , 的图象称为正态曲线。
正态分布的期望与方差 若 ,则:
正态曲线的性质
① 曲线在 轴的上方,与 轴不相交;
② 曲线关于直线 对称;
③ 曲线在 时达到峰值 ;
④ 曲线与 轴之间的面积为 ;
⑤ 当 时,曲线上升;当 时,曲线下降。并且当曲线向左右两边无限延伸时,以 轴为渐近线,向它无限靠近;
⑥ 曲线的形状由 确定: - 越大,峰值 越小,曲线越“矮胖”,表示总体的分布越分散; - 越小,峰值 越大,曲线越“瘦高”,表示总体的分布越集中。
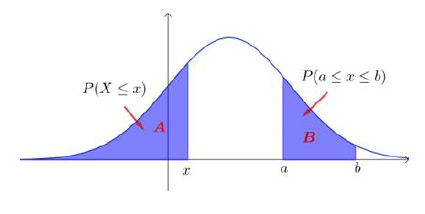
- 正态分布的概率含义 若 ,则: - 取值不超过 的概率 为曲线下 区域的面积; - 为曲线下 区域的面积。
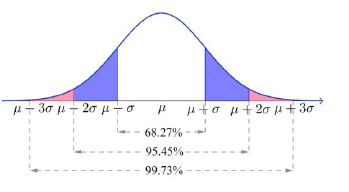
- 3σ原则 假设 ,对于给定的 , 是一个只与 有关的定值。
特别地: \begin{align*} P(\mu - \sigma < x \leq \mu + \sigma) &= 0.6827 \\ P(\mu - 2\sigma < x \leq \mu + 2\sigma) &= 0.9545 \\ P(\mu - 3\sigma < x \leq \mu + 3\sigma) &= 0.9973 \end{align*} 在实际应用中,通常认为服从于正态分布 的随机变量只取 之间的值,并简称之为 3σ 原则。 -
- 标准正态分布
① 在标准正态分布表中,相应于 的值 是指总体取值小于 的概率,即 。 - 时, 的值可在标准正态分布表中查到; - 时,可利用其图象的对称性获得 来求出。 区间概率计算:
② 与 的关系:
(i) 若 ,则 ,有 ;
(ii) 若 ,则 。
⚠️ 考场避坑与做题技巧
利用对称性解题的“黄金法则”
在填空选择题中,若已知 ,求 或类似区间,务必画出草图。利用 以及关于 对称的等面积特性,可以快速得出结论。
参数是 还是 ?
题目给出 时,意味着 。计算 区域时一定要先开方,很多同学会直接用 4 进行计算,导致结果偏差巨大。
Link to original“小概率事件”的判定
根据 原则,数值落在 之外的概率仅为 。在质量检测等实际问题中,如果出现此类数值,通常认为发生了异常,即“小概率事件在一次实验中发生了”,从而判定生产过程失控。






第 24 章 统计
24.00 知识网络
Link to original

24.01回归分析与线性拟合
🟦 回归分析与线性拟合
核心心法
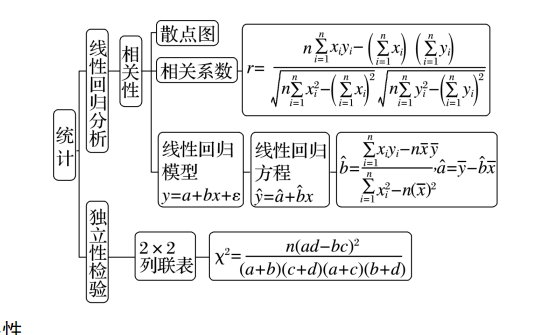
“散点定趋势,系数定强弱,方程定预测”。回归分析的本质是寻找一条“最优”直线,使得所有样本点到该直线的距离平方和最小。通过相关系数 判定线性相关的紧密程度,通过决定系数 评估模型的拟合优度,而回归方程 则是实现数据外推预测的数学载体。
一、 变量间的相关关系
- 关系分类:
- 函数关系:确定性的关系(如 )。
- 相关关系:非确定性的关系(如身高与体重)。
- 散点图与正负相关:
- 正相关:点群从左下向右上延伸。
- 负相关:点群从左上向右下延伸。
二、 相关系数 (Correlation Coefficient)
用于衡量两个变量 与 之间线性相关程度的量:
1. 的性质
- 符号判定: 为正相关, 为负相关。
- 程度判定: 越接近 1,相关性越强; 越接近 0,相关性越弱。
- 强相关标准:通常 即可认为具有很强的线性相关关系。
三、 线性回归方程
1. 最小二乘法系数公式
2. 核心性质
样本中心点
回归直线 一定经过样本点的中心 。这是求解截距 的关键依据。
四、 拟合效果的评估:残差与决定系数
- 残差 (Residual):。实际观测值与模型估计值的偏差。
- 残差平方和 :。 越小,拟合效果越好。
- 决定系数 (Coefficient of Determination):
- 物理意义: 对 变化的贡献率。
- 判定: 越接近 1,模型拟合效果越好。
五、 非线性回归的线性化转化
当散点图呈现曲线特征时,通过变量代换将其转化为线性回归:
原非线性方程 变量代换方法 转化后的线性形式 指数型 两边取对数,令 () 幂函数型 令
⚠️ 考场避坑与做题技巧
公式选择的“偷懒”法则
- 如果题目给了一堆散点坐标,先算 ,用第一组减法公式。
- 如果题目给出了 这种整体和,直接套用第二组乘法公式。
相关性不代表因果性
统计学上的相关关系只能说明两个变量在数值上有同步趋势,并不代表 是 的原因。在描述结论时,要用“相关”而非“因为”。
Link to original与 的联系
在简单线性回归中, 实际上等于相关系数 的平方。所以如果 很大, 自然也会接近 1。

24.02 独立性检验与 2X2 列联表
🟦 独立性检验与 列联表
核心心法
“假设无关,卡方验证,查表定论”。独立性检验的本质是考察观测频数与理论频数的偏离程度。卡方值 越大,说明观测数据与“无关假设”的偏离越严重,我们就越有信心认为两个分类变量之间存在相关性。
一、 核心流程与列联表结构
Step 1. 完善 列联表
首先将实验数据填入下表,并计算行列合计:
总计 总计
二、 假设与计算
Step 2. 提出零假设
- 假设内容::变量 和 相互独立(或: 与 无关、无差异)。
Step 3. 计算卡方统计量
利用公式计算偏离程度:
- 其中 为总样本容量。
三、 查表与判定结论
Step 4. 查对临界值表 (Critical Values)
根据题目给定的小概率值 ,找到对应的临界值 :
0.10 0.05 0.025 0.010 0.001 2.706 3.841 5.024 6.635 10.828 Step 5. 下结论
- 若 : 在小概率值 的独立性检验下,拒绝 。即认为变量 和 有关,且该判断犯错的概率不超过 。
- 若 : 没有充分证据证明 不成立,可以认为 成立。即认为变量 和 无关。
🚀 深度拓展:卡方公式的结构逻辑
- 的意义: 若 与 完全独立,则应满足比例相等 ,即 。因此 的差值越大,说明独立性越差,相关性越强。
- 分母的作用: 分母是四个边际合计的乘积,起到了标准化的作用,使不同样本规模下的数据具有可比性。
⚠️ 考场避坑与做题技巧
结论描述的专业性
在书写大题结论时,必须带上前提:“根据小概率值 的独立性检验…”。这体现了统计推断的严谨性,即结论是在概率意义下成立的,而非绝对确定。
计算精确度控制
计算 时,中间步骤尽量保留分数或多位小数。尤其是分母的四个数相乘通常很大,若提前四舍五入,最终得到的卡方值可能会由于跨过临界值而导致结论完全相反。
Link to original独立性不代表因果性
即使 很大,判定 与 有关,也仅说明它们在统计上存在相关性,并不能直接推断出 是导致 的根本原因。
备考逻辑
- 计数要严谨:排列组合题目务必检查是否“重”或“漏”,优先使用特殊元素/位置优先法。
- 模型要准确:区分放回抽样(二项分布)与不放回抽样(超几何分布)。
- 数据要客观:在统计大题中,计算回归方程时务必细心,关注 和 的实际含义。